This article explains data structures in Bitcoin. One of the important concepts to be used here is the hash pointer. A normal pointer stores the address of a structure in memory. For example, if there is a structure and p is a pointer to the structure, then p holds the starting position of the structure in memory. The hash pointer has to hold the hash value of the structure in addition to this address. Generally, a hash pointer is denoted by H( ). The advantage of this is that from this hash pointer, not only can we find the location of the structure, but we are also able to detect whether the content of the structure has been tampered with, because we have saved its hash value. One of the most basic data structures in Bitcoin is the blockchain. What is a blockchain? It’s a linked list of blocks. What’s the difference between a blockchain and a regular linked table? One difference is the use of hash pointers instead of normal pointers.
We can draw an example of a small blockchain. The block at the top is the first block produced in the system, called the genesis block, and the block at the end is the most recently produced block. Each block contains hash pointers to the previous block, which are small hash pointers, and this last block also has a hash pointer saved in the system. What is the benefit of this data structure? When taking the hash, the contents of the entire block are combined to take the hash. For example, how is the hash pointer of a block calculated? Is the content of the entire block, including the inside of the hash pointers together to take the hash, calculated hash value. Through such a data structure can be realized tamper-evident log.
If a person tampered with the contents of a certain place in the blockchain, what would happen? After the content of this place is changed, the hash pointer of the block behind can not be corrected, because it is based on the content of the entire block in front of the calculation, so the hash pointer of the block behind also has to be changed, and then the hash in the next block can not be corrected, so it also has to be changed, in the end, the hash retained in the system also has to be changed, and the hash value of this system is that we have preserved the value of the hash, so the benefits of this data structure is that Modifications to any part of the blockchain can be detected as long as the last hash is memorized. No matter what part of the blockchain the change is made, it will end up causing the saved system hash value to change. This is one difference between a blockchain and a regular linked table. In a normal chain table, you can change one of the elements and it has no effect on the other elements in the chain table, whereas a blockchain affects the whole body. Changing any block in front of it will trigger a domino effect, and all the blocks behind it will have to be changed, so as long as you save the hash value of the last block, you will know if you have changed any part of the blockchain.
This property of blocks makes it possible for some nodes in Bitcoin to not necessarily save the entire blockchain, but to save only the most recent thousands of blocks, and not anything further back. If you want to use a previous block, you can ask another node in the system for it. Some nodes may be malicious, this is a decentralized system, so how do you know if the block given to you by someone else is correct, which uses this property of the hash pointer.
For example, only the last few blocks are saved, the previous ones are not saved, and I need to use the previous blocks, I ask someone for them. If someone gives me a block like that, I can see if it’s the right one by counting their hash against the one I saved.
Another data structure in bitcoin is the merkle tree. you’ve heard of a binary tree before. what’s the difference between a merkle tree and a binary tree? One difference is that it uses a hash pointer instead of a normal pointer. You can draw an example of a merkle tree.
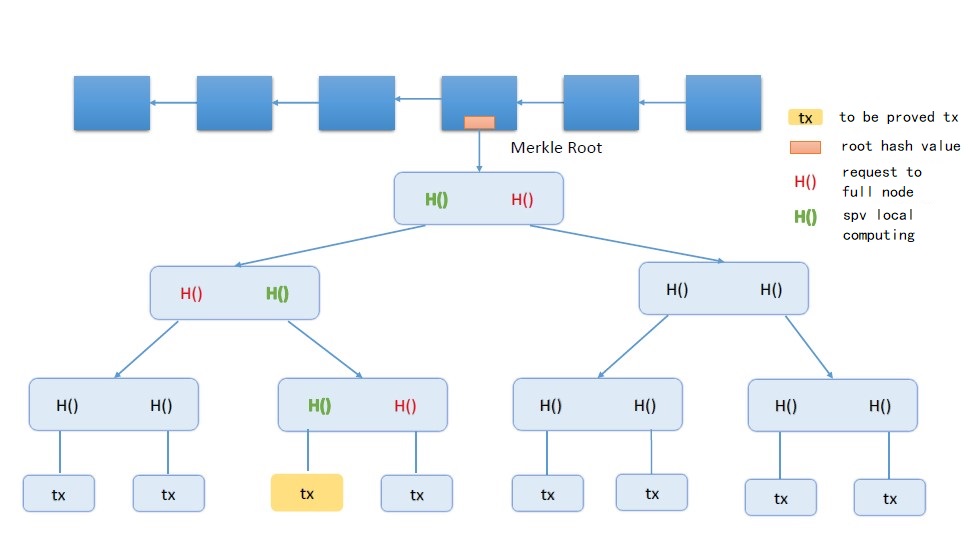
Above is a merkle tree, the bottom layer is a data block date block, above these internal nodes are hash pointers, such as a data block below, its hash value exists above the corresponding node. Next to the data block hash value also exists above the corresponding node, the two hash values together, and then take the hash exists in the upper node, next to the branch is the same, and finally the root node. This layer by layer push up, the root node can also take the hash, called the root hash.
What are the benefits of such a data structure? Just by remembering this root hash you can detect modifications to any part of the tree. The blockchain hash pointers form a linked table, and modifications to any part of this linked table can be detected by remembering this last hash value. This is similar, a little more efficient, it is a binary tree form, as long as you remember the top of the root node of the hash value, then the entire tree is protected, if there is a certain place for modification, can be detected. This is one of the characteristics of a merkle tree. Bitcoin, each block is connected to each other with a hash pointer, and the transactions contained in each block are organized into a merkle tree, and each data block under this merkle tree is actually a transaction transaction.
Each block is divided into two parts, block header and block body block body.
Inside the block header there is a root hash value, that is, the block contains all the transactions composed of merkle tree root hash value is present in the block header, but the block header does not have the specific content of the transaction, there is only a root hash value. block body has a list of transactions.