This section talks about the specific implementation of the Bitcoin system.
The blockchain is a decentralized ledger, and Bitcoin uses a transaction-based decentralized ledger model. Recorded in each block is transaction information, there are transfer transactions and minting transactions. But nowhere in the Bitcoin system is there an explicit record of how much money is on each account. For example, if you want to know how much money is in account a, you need to use the transaction logs to figure out how many transfers have been made to address a, how many coins have been transferred, how many of those coins have been spent, and how many haven’t, so that you can figure out what the current balance of account a is.
The entire node of the Bitcoin system maintains a data structure called UTXO (Unspent Transaction Output) – the output of transactions that have not yet been spent. That is, there are a lot of transactions on the blockchain, and the output of some of them may have already been spent, and some of them haven’t been spent yet. The set consisting of the outputs of all those transactions that haven’t been spent yet is this UTXO.
Note that a transaction may have more than one output. For example, a transfer transaction for a might be 5 bitcoins to b and 3 bitcoins to c. B gets the 5 bitcoins and spends them, so this output is not in the UTXO. c receives the 3 bitcoins and hasn’t spent them yet, so this output is in the UTXO. That is, the same transaction may have some output in UTXO and some output not in this UTXO.
Each element in the UTXO collection has to give the hash of the transaction that produced this output, and the fact that it is the first output in this transaction. These two pieces of information will locate the output in this UTXO. So what is the purpose of this UTXO collection, and why is it necessary to maintain such a data structure? It’s to detect double spending, that is, whether a newly released transaction is legitimate or not, we have to check this UTXO, the coins you want to spend are only legitimate if they are in the UTXO collection. If it is not in this set, it means that the coin you want to spend either does not exist or has been spent before, so the whole node has to maintain a data structure like UTXO in memory in order to quickly detect double spending.
Each transaction consumes some of the unspent output and also generates new unspent output. In the above example, a transfers 5 bitcoins to b, b spends them, and b gives them to d. At this point, b’s unspent output is used up by b’s unspent output, and b’s unspent output is used up by b’s unspent output. At this point, b’s unspent output is no longer in UTXO, but a new unspent output is created. This new unspent output is again saved in UTXO. That is, as transactions are posted, each transaction consumes some UTXO of this underspent output, but then generates some new underspent output. If someone receives a bitcoin transfer transaction and that money is never spent, then that information is always saved in UTXO. For example, Satoshi Nakamoto, the legendary inventor of Bitcoin, just doesn’t spend it. Others may want to spend it, but there is no way to spend it because he lost the key, and these things belong to be kept in UTXO permanently. The statistics on the blockchain show that this collection of UTXOs is gradually growing, but so far it is still perfectly fine to fit in the memory of an average server. Each transaction can have multiple inputs and multiple outputs, and the sum of all the inputs must equal the sum of all the outputs, which is called total inputs = total outputs, and the example above gives two examples of outputs. There can be more than one input, and the inputs do not have to come from the same address. This is why a transaction may require multiple signatures, one for each input address.
In some transactions, the total inputs are slightly larger than the total outputs. For example, if the total inputs are 1 bitcoin and the total outputs are 0.99 bitcoin, the difference of 0.01 bitcoin is paid as a transaction fee to the node that gets the right to post the block. As mentioned in the previous section, nodes have to consume computational resources to compete for this bookkeeping right and get the reward for posting a block. There is a special coinbase transaction for posting a block that pays a certain amount of bitcoins, the so-called block reward, but this block reward alone may not be enough. Why should the node posting the block package your transaction into the block, and what’s in it for him?
If a selfish node releases a block, he may want to include only his own transactions, but not any other transactions. Because there is no benefit for him to pack other transactions in, and there is a certain cost, because you have to verify the legitimacy of the transaction, and if the block is packed with more transactions, it takes up more bandwidth, and the speed of propagation on the network will be slower, so if there is only a block reward mechanism, there may be some cases that the node is more selfish, it doesn’t care about other people’s transactions, it only packs its own transactions. So the Bitcoin system has designed a second incentive, which is a transaction fee.
It’s called a transaction fee. It’s kind of a tip. I’ll give you a little bit of a tip for packing my transaction into the block. Currently, transaction fees in the Bitcoin system are very small, and there are some simple transactions that don’t have a transaction fee. At the moment, the main reason that miners are mining to compete for this bookkeeping right is to get the reward for getting out of the block. Because that’s 12.5 bitcoins, but as I said earlier, the block reward is going to be gradually reduced by half every 210,000 blocks. 210,000 blocks is roughly how long is that? The Bitcoin system is designed to have an average block time of ten minutes, which means that the entire Bitcoin system, on average, generates a new block every ten minutes, which, if you do the math, is about four years. To generate 210,000 blocks, on average, it takes about four years. In other words, every four years, the block out reward is cut in half. Then many years from now, that block-out reward may become very small, and at that point, maybe the transaction fees become the main thing.
In addition to Bitcoin’s transaction – based ledger, there’s another model that corresponds to it, which is an account – based ledger. Ether, which we’ll talk about later, uses this account – based ledger, in which the system explicitly records how many coins are in each account. It’s a lot closer to what we experience every day, like if you want to know the balance of your bank account, you log into your bank account and you can find out. The transaction-based model of Bitcoin is a little bit more privacy-protective, but there are some costs. For example, as we’ve talked about a number of times in previous content, transfer transactions in Bitcoin have to specify the origin of the coins.
Below we look at some specific examples on the blockchain to see specific block information in the Bitcoin system.
An example of a block. This is an image taken from the website blockchain.info.
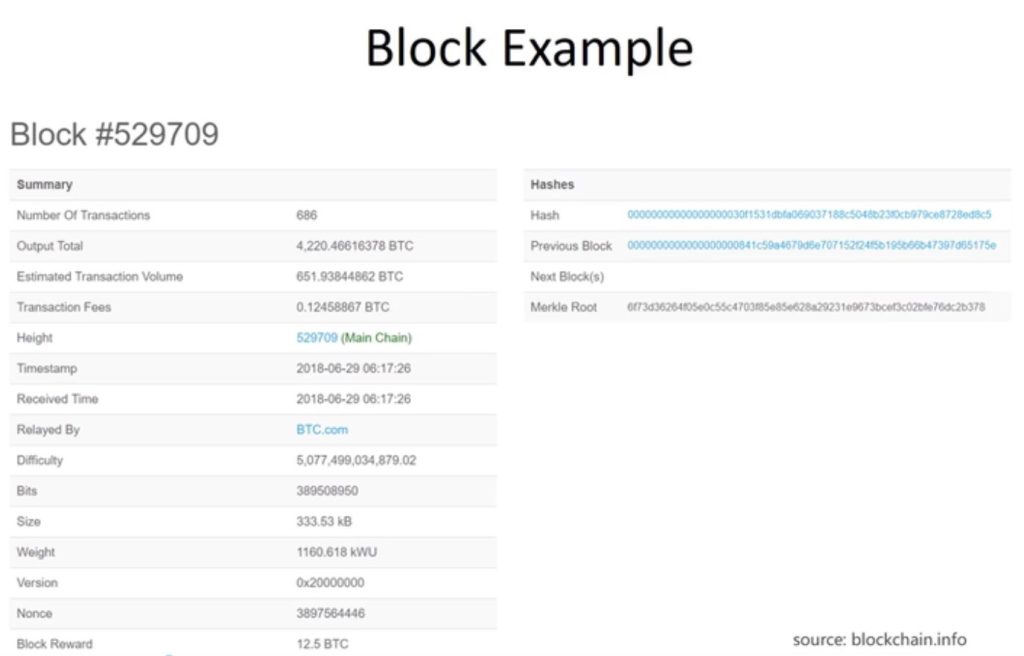
It shows that the block contains 686 transactions; the total output in bitcoins; the total transaction fee, which is the sum of the transaction fees for the 686 transactions in the block; and the bottom line is the block reward. You can compare the difference between the two is about 100 times, the block reward is still the majority, compared to the transaction fee, the block reward is about 100 times the transaction fee, which is the main incentive for miners to mine, in order to get the block reward. inside the Height is the serial number of the block; Timestamp is the timestamp of the block, which is the time when the block was created; Difficulty is the difficulty of mining, every 2016 blocks to adjust the difficulty, to keep the time out of the block in about ten minutes; Nonce is the random number of mining attempts, here the nonce value is the last found to meet the difficulty requirements.
The right side shows three hash values, the first is the block header hash value of this block, the second is the block header hash value of the previous block, note that the calculation of the hash value, are only counted block header, does not contain a specific list of transactions in the block body.
What are the common characteristics of these two hash fingers? Both have a long string of zeros in front of them. The hash of a block and the hash of the previous block both have a long string of zeros at the beginning. This is not by chance, as mentioned earlier, the so-called mining, is to constantly adjust the random number of nonce, so that the hash value of the entire block header is less than or equal to a given target threshold. This target threshold is expressed in hexadecimal is a long series of zeros in front, so all the blocks that meet the difficulty requirements, its block header hash value is calculated to have a long series of zeros.
The third is the Merkle Root, which is the root hash value of the merkle tree consisting of those transactions contained in this block.